multimodal interaction
Overview:
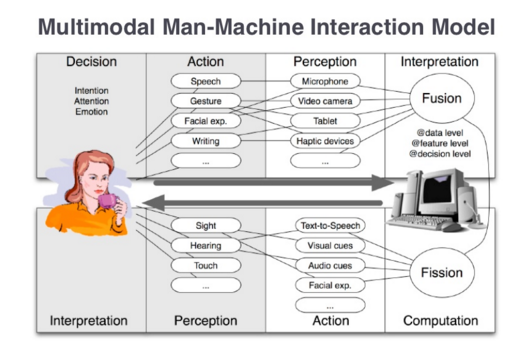
Multimodal Interaction is a situation where the user is provided with multiple modes for interacting with the system. Multi-modal systems as those that process two or more combined user input modes such as speech, touch, visual and learning in a coordinated manner with multimedia system output
Multimodal Interaction is a situation where the user is provided with multiple modes for interacting with the system. Multi-modal systems as those that process two or more combined user input modes such as speech, touch, visual and learning in a coordinated manner with multimedia system output
Sequential Multimodal: means user will have to switch between the modes of interaction but cannot use the modes together.
Simultaneous Multimodal: allows user to use more than one mode at a time to interact with the system. For example: in route finder application the user could say “Show me the quickest route from here and here” while indicating the two locations on an on-screen map using touch.
Fusion of inputs from multiple modals uses strengths of one mode to compensate for weaknesses of others like design time and run time.
General Requirements of MMI Interfaces:
More information on MMI requirements, specification is defined by W3C in the following link:
http://www.w3.org/TR/mmi-reqs/
Input/ Output Modes:
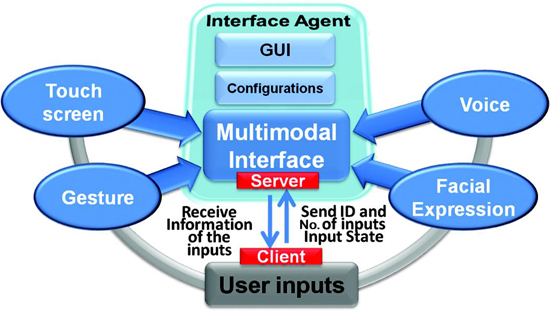
Multimodal interaction revolves around having certain modes which take the various forms of input, combine them seamlessly, process and give the feedback or output in one or the other output modes.
Simultaneous Multimodal: allows user to use more than one mode at a time to interact with the system. For example: in route finder application the user could say “Show me the quickest route from here and here” while indicating the two locations on an on-screen map using touch.
Fusion of inputs from multiple modals uses strengths of one mode to compensate for weaknesses of others like design time and run time.
General Requirements of MMI Interfaces:
- Supplementary and complementary use of different modalities
- Seamless synchronization of modalities
- Multilingual support
- Easy to implement
- Accessibility
- Security and privacy
- Delivery and context
- Navigation specification
More information on MMI requirements, specification is defined by W3C in the following link:
http://www.w3.org/TR/mmi-reqs/
Input/ Output Modes:
Multimodal interaction revolves around having certain modes which take the various forms of input, combine them seamlessly, process and give the feedback or output in one or the other output modes.
Input Modes:
Visual:
Visual interaction is implicit interaction which can help automotive UIs to better support attention switching and interaction. Therefore automotive interfaces must support these tasks accordingly while maintaining driving safety at the same time. One major question of automotive user interfaces is the location of input elements (ranging from buttons to interactive surfaces) and displays as output devices. Depending on the position, the effort to locate an input element or to direct the view to the screen differs.
Visual:
Visual interaction is implicit interaction which can help automotive UIs to better support attention switching and interaction. Therefore automotive interfaces must support these tasks accordingly while maintaining driving safety at the same time. One major question of automotive user interfaces is the location of input elements (ranging from buttons to interactive surfaces) and displays as output devices. Depending on the position, the effort to locate an input element or to direct the view to the screen differs.

Touch:
Using a simple touch gesture, the interaction style lowers the visual demand and provides at the same time immediate feedback and easy means for undoing actions. After the selection of the interaction object(s) and function, the user can perform a gesture to complete the intended action. This form of interaction (e.g. moving a finger up and down on a touchpad) allows for a fine-grained manipulation and provides simple means for undo of an action. As the action is executed at the same time, immediate feedback is given by means of manipulating the objects, e.g. the windows are lowered as the user moves the finger over the touchpad.
Using a simple touch gesture, the interaction style lowers the visual demand and provides at the same time immediate feedback and easy means for undoing actions. After the selection of the interaction object(s) and function, the user can perform a gesture to complete the intended action. This form of interaction (e.g. moving a finger up and down on a touchpad) allows for a fine-grained manipulation and provides simple means for undo of an action. As the action is executed at the same time, immediate feedback is given by means of manipulating the objects, e.g. the windows are lowered as the user moves the finger over the touchpad.

Speech:
By using speech for identification of functions, we exploit the visibility of objects in the car (e.g., mirror) and simple access to a wide range of functions equaling a very broad menu. Speech is used to select and qualify one or multiple objects (e.g., “window”) and their function (e.g., “open”) to be manipulated. If an object offers only one function that can be manipulated, the selection process can be as short as just saying the name of this object and implicitly choosing its function, e.g., “AC”.
By using speech for identification of functions, we exploit the visibility of objects in the car (e.g., mirror) and simple access to a wide range of functions equaling a very broad menu. Speech is used to select and qualify one or multiple objects (e.g., “window”) and their function (e.g., “open”) to be manipulated. If an object offers only one function that can be manipulated, the selection process can be as short as just saying the name of this object and implicitly choosing its function, e.g., “AC”.

Output Modes
Text:
The output or the feedback is displayed as a text message or prompt to the user. This leads to a bit of distraction and not recommended as a standalone mode of output.
Audio:
Voice prompts are part of this output mode. Usually they are short affirmations for any speech commands issued by the user, or warnings and alerts when an issue arises.
Text:
The output or the feedback is displayed as a text message or prompt to the user. This leads to a bit of distraction and not recommended as a standalone mode of output.
Audio:
Voice prompts are part of this output mode. Usually they are short affirmations for any speech commands issued by the user, or warnings and alerts when an issue arises.
Learning:
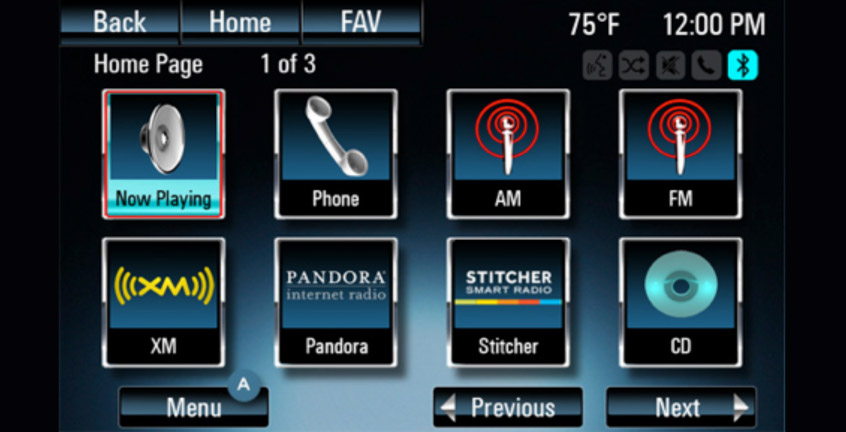
Learning mode involves two sub modes called “Learning Text” which allows user to get trained with regards to placement of icons and recognizing every icon by sight. Below every icon is a one word descriptive text that will give the user an idea of what the icon does and the command used in speech recognition. And “Learning Voice” allows user to get trained with respect to the multimodal functionality and experiencing less cognitive challenge. For example: The user said play track 15 by Enrique but this command is not acceptable by the dialogue system but system will check all possible options and will speak back to the user. IF user touches any icon then system will echo the speech command corresponding to that icon. This way user will get to learn the commands. This mode can be turned on and off as per the user convenience.
Learning mode involves two sub modes called “Learning Text” which allows user to get trained with regards to placement of icons and recognizing every icon by sight. Below every icon is a one word descriptive text that will give the user an idea of what the icon does and the command used in speech recognition. And “Learning Voice” allows user to get trained with respect to the multimodal functionality and experiencing less cognitive challenge. For example: The user said play track 15 by Enrique but this command is not acceptable by the dialogue system but system will check all possible options and will speak back to the user. IF user touches any icon then system will echo the speech command corresponding to that icon. This way user will get to learn the commands. This mode can be turned on and off as per the user convenience.
Challenges and Opportunities
Challenges in MMI:
Despite the significant progress on multimodal interaction systems in recent years, much work remains to be done before sophisticated multimodal interaction becomes a commonplace, indispensable part of computing.
Multimodal input Integration:
One of the biggest challenges is multimodal integration methods and architectures need to explore a wider range of methods and modality combinations. User’s actions or commands produce multimodal inputs, which have to be interpreted by the system. It is obtained by merging information that is conveyed via several modalities by considering the different types of cooperation between several modalities. An ambiguity arises when more than one interpretation of input is possible. So Problem and contradiction occurs between various inputs. . Modalities with very different characteristics – e.g., speech and eye gaze, facial expression and haptics input, touch-based gesture and prosody-based affect – may not have obvious points of similarity and straightforward ways to connect.
Article: how robots learn and overcome obstacles when multimodal inputs are contradictory.
http://www.sciencedirect.com/science/article/pii/S0921889014000396
Security and Privacy Issues:
Electronic security is one of the major concerns for all the people. Hackers, dis-satisfied employees, anti-social element organizations may target automated vehicles and intelligence systems resulting in traffic concerns and accidents.
GPS Spoofing can also be done which leads to false destinations and lead to kidnapping. Privacy is one of the basic rights and not a privilege. Thus, it is the primary responsibility to ensure that the input received in cars does not violate privacy of an individual.
An article on a GPS Spoofing incident:
http://www.digitaltrends.com/mobile/gps-spoofing/
Opportunities in MMI:
Multimodal interaction has a number of opportunities to be used in various applications because:
Multimodal In-Car Enhanced Interaction System:
Workload and distraction suggest that increasing the complexity of a speech-based interface may impose a greater cognitive load. Multimodal interfaces are recognized to be inherently flexible, and to provide an especially ideal interface for accommodating both the changing demands encountered during mobile use and also the large individual differences present in the population. Multimodal provides the necessary advantages and reduces driver load and distraction.
Challenges in MMI:
Despite the significant progress on multimodal interaction systems in recent years, much work remains to be done before sophisticated multimodal interaction becomes a commonplace, indispensable part of computing.
Multimodal input Integration:
One of the biggest challenges is multimodal integration methods and architectures need to explore a wider range of methods and modality combinations. User’s actions or commands produce multimodal inputs, which have to be interpreted by the system. It is obtained by merging information that is conveyed via several modalities by considering the different types of cooperation between several modalities. An ambiguity arises when more than one interpretation of input is possible. So Problem and contradiction occurs between various inputs. . Modalities with very different characteristics – e.g., speech and eye gaze, facial expression and haptics input, touch-based gesture and prosody-based affect – may not have obvious points of similarity and straightforward ways to connect.
Article: how robots learn and overcome obstacles when multimodal inputs are contradictory.
http://www.sciencedirect.com/science/article/pii/S0921889014000396
Security and Privacy Issues:
Electronic security is one of the major concerns for all the people. Hackers, dis-satisfied employees, anti-social element organizations may target automated vehicles and intelligence systems resulting in traffic concerns and accidents.
GPS Spoofing can also be done which leads to false destinations and lead to kidnapping. Privacy is one of the basic rights and not a privilege. Thus, it is the primary responsibility to ensure that the input received in cars does not violate privacy of an individual.
An article on a GPS Spoofing incident:
http://www.digitaltrends.com/mobile/gps-spoofing/
Opportunities in MMI:
Multimodal interaction has a number of opportunities to be used in various applications because:
- Provides transparent, flexible, and powerfully expressive means of HCI.
- Easier to learn and use.
- Robustness and Stability.
- If used as front-ends to sophisticated application systems, conducting HCI in modes all users are familiar with, then the cost of training users would be reduced.
- Potentially user, task and environment adaptive.
- Support shorter and simpler speech utterances than a speech-only interface,
Multimodal In-Car Enhanced Interaction System:
Workload and distraction suggest that increasing the complexity of a speech-based interface may impose a greater cognitive load. Multimodal interfaces are recognized to be inherently flexible, and to provide an especially ideal interface for accommodating both the changing demands encountered during mobile use and also the large individual differences present in the population. Multimodal provides the necessary advantages and reduces driver load and distraction.
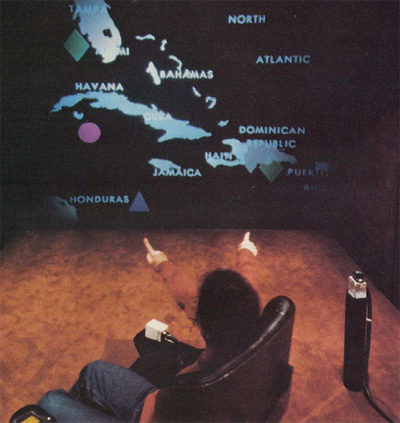
Put-that-there:
“Put That There” is a voice and gesture interactive system implemented at the Architecture Machine Group at MIT. It allows a user to build and modify a graphical database on a large format video display. The goal of the research is a simple, conversational interface to sophisticated computer interaction. Natural language and gestures are used, while speech output allows the system to query the user on ambiguous input. This project starts from the assumption that speech recognition hardware will never be 100% accurate, and explores other techniques to increase the usefulness (i.e., the “effective accuracy”) of such a system.
“Put That There” is a voice and gesture interactive system implemented at the Architecture Machine Group at MIT. It allows a user to build and modify a graphical database on a large format video display. The goal of the research is a simple, conversational interface to sophisticated computer interaction. Natural language and gestures are used, while speech output allows the system to query the user on ambiguous input. This project starts from the assumption that speech recognition hardware will never be 100% accurate, and explores other techniques to increase the usefulness (i.e., the “effective accuracy”) of such a system.